Data Engineering for Beginners


Basics in Data Engineering
Basics are not SQL or Python. If you want to learn Data Engineering you need to understand DATA FUNDAMENTALS first
Before jumping on such a robust language like Python, it’s better to understand WHERE you need to apply it and in which context.
The beginning of my career started with Python and zero knowledge about Data Engineering, so instead of leveraging Python for let’s say batch pipelines, I was wasting my time studying Django and Flask frameworks which are cool, but not a 100% match. I can’t say that it was a complete waste of time, but I’d take it differently.
For that I’m going to share you which concepts and approaches are used in Data Engineering first:
Here is the list of all the concepts mentioned in today’s video
I’m using Scrintal to showcase this beautiful mindmap. I’m going to share the link below with more detailed information about each point and sources in case you are a deep diver.
⚡️ Link to Mindmap:
https://bit.ly/data-engineer-basics-mindmap
⚡️ Get 10% off Scrintal Personal Pro. Try it today. Code "NATAINDATA" is valid for 4 weeks after the video is out.
Anyone who follows the link will get a discount automatically:
https://scrintal.com/?utm_source=YT&utm_medium=PNS&utm_campaign=A10575&d=NATAINDATA
------------
DATABASE TYPES
Originally, the offsprings of data engineering were database administrators.
They were managing SQL or Relational databases which organize data in rows and tables, ideal for complex queries and transactional operations.
Then data varieties expanded. So NoSQL databases came into the picture to handle unstructured data like documents and real-time analytics, providing flexibility where traditional schemas did not fit.
Similarly, graph databases, which store data in nodes and edges, are perfect for analyzing complex relationships, and vector databases are crucial in fields like machine learning where high-performance data retrieval is essential. And it is on the verge of aligning with the GenAI trend.
But let’s go back to offsprings and their SQL databases
DATA MODELLING
So are we just throwing whatever we have in the database?
Not really. First, we model. Data model means structuring your data into a format that is both efficient and usable.

Common techniques include the Star Schema, where a central fact table links to several dimension tables. And the Snowflake Schema, which is a more normalized version, reducing data redundancy.
Then Third Normal Form (3NF) - here we reduce redundancy and dependency and make tables normalised.
Em, what do I mean by that? There are a couple of techniques or forms, like 1NF - First Normal Form - tables should contain only atomic values, meaning no repeating groups, then 2NF, 3NF, etc.
Data Vault as well - hybrid of Star and 3NF because here we have: Hubs (key business concepts), Links (associations between Hubs), and Satellites (descriptive data, like dimensions). It’s great for historical data tracking and flexible in schema change
speaking of historical tracking…
SCD & CDC
As data changes over time, how we track and manage these changes becomes crucial. Slowly Changing Dimensions (SCD) deal with managing historical data changes without losing the history. We can do that with Overwriting and forgetting the rows, or adding new rows and marking them with timestamp or adding more columns.
Whereas Change Data Capture (CDC) focuses on identifying and capturing changes in real-time, allowing systems to stay up-to-date.
DATA WAREHOUSE & DISTRIBUTED SYSTEMS
So is knowledge of databases is enough?
Not only. You will work mostly with data warehouses - it’s like databases on steroids.
Now they often use distributed systems to manage the increasing volume, variety, and velocity of data (the three Vs of big data). You need to understand here deeply the CAP theorem, which says that a system can only provide two out of three guarantees: Consistency, Availability, and Partition Tolerance.
In simple terms, it's like saying in a network of computers, you can't have perfect up-time, perfect data uniformity, and perfect resilience to network failures all at once—you have to pick two.
Em, why so complicated?
Ah, Evolution!
DATA EVOLUTION
Data warehouses matured. In short, we went from SMP to MPP to EPP. Hihi.
What does it mean?
It all started in 70’s with SMP or Symmetric Multiprocessing (SMP) hardware for database system which executed instructions using shared memory and disks.
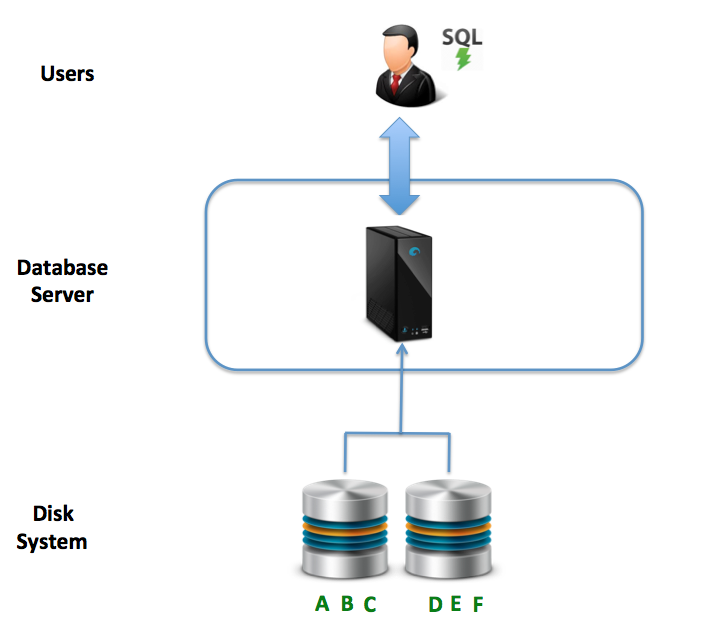
But then In 1984, Teradata delivered its first production database using MPP - a Massively Parallel Processing architecture [ Forbes magazine named Teradata “Product of the Year” ]
It’s like SMP server accepts user SQL statements, which are distributed across a number of INDEPENDENTLY running database servers that act together as a single clustered machine. Each node is a separate computer with its own CPUs, memory, and directly attached disk.
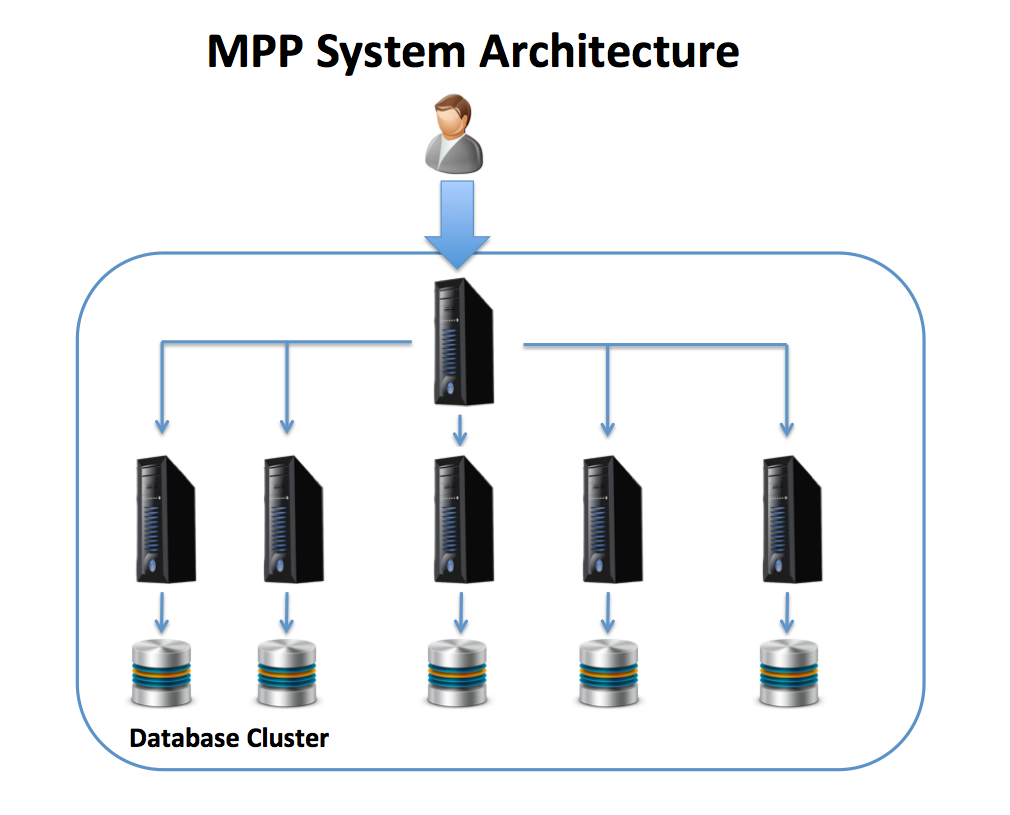
It was a blast! But had many drawbacks in terms of Complexity and cost, Data distribution, lack of elasticity
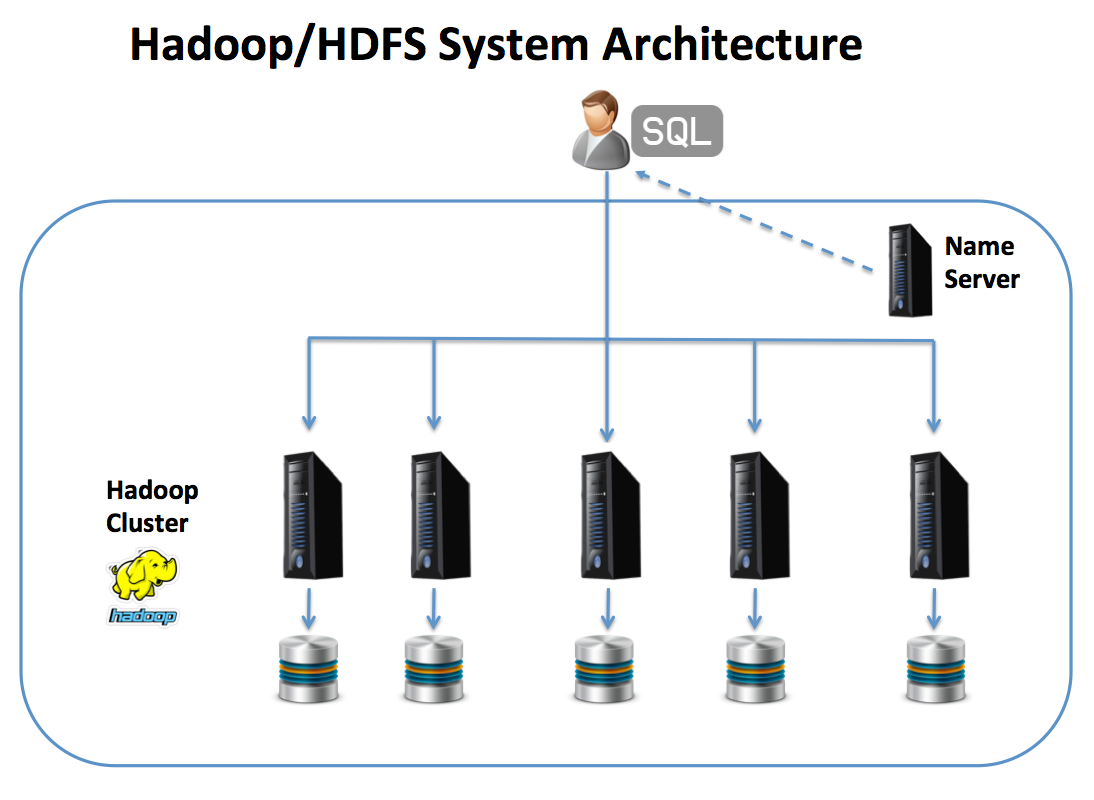
Then Hadoop kicked in. Hadoop is a complementary technology, not a replacement here
It’s similar to MPP architecture, but with a twist:
The Name Server acts as a directory lookup service to point the SQL query to the node(s) upon data will be stored or queried from.
Plus MPP platform distributed individual rows across the cluster, Hadoop simply breaks the data into arbitrary blocks, which are then replicated.
Then the next break through was EPP
Elastic Parallel Processing - which is literally separating compute and storage layers.
unlike the MPP cluster in which data storage is directly attached to each node, the EPP architecture separates the layers, which can be scaled up or scaled out independently.
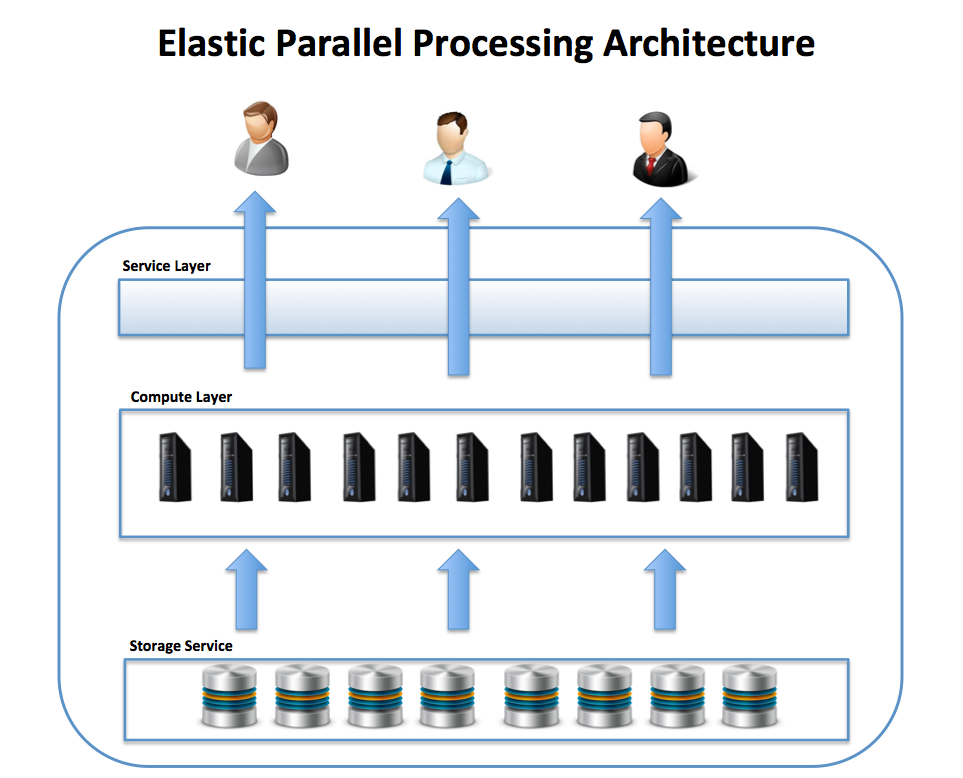
Nowadays all major players like Snowflake, Databricks, AWS, Google, Microsoft are using those for their datawarehouses under the hood.
Unlike the SMP system, which is inflexible in size, and both Hadoop and MPP solutions, which are at risk of over-provisioning, an EPP is super flexible!
DATA ANALYSIS
So noooow let’s talk about Big Data and its analysis. There are two types of data processing systems used for different purposes:
OLAP (Online Analytical Processing) and OLTP (Online Transaction Processing):
- OLAP is all about analysis. Think of column-oriented data warehouse. It’s optimised for read operations, like complex queries with aggregating and analyzing data. These systems are optimized for speed in querying
- OLTP is focused on handling a large number of short transactions quickly. It’s optimised for write operations: INSERT, UPDATE, and DELETE. Think of processing when you book a flight online or make a purchase. Here data integrity and speed are at MAXIMUM.
And how do we move the data? We have common approaches for that: ETL or ELT
- ETL - extracts data from various sources, transforms it into a consistent format, and loads it into a target system or data warehouse.
- ELT - almost the same as before, but after extracting we load data (in Data lake as is), and then transform as needed. So our raw data is secured and analysis could be performed later on.
Here you have it dears! Curious to know if you liked this format, please tell me if you want more:)