Python for Data Engineering


How I use Python as a Data engineer:
Python plays a vital role in my daily work as a data engineer. In this guide, I’ll share tips, best practices, and insights into how I use Python effectively as a Senior Data Engineer.
[source: https://datanerd.tech/]
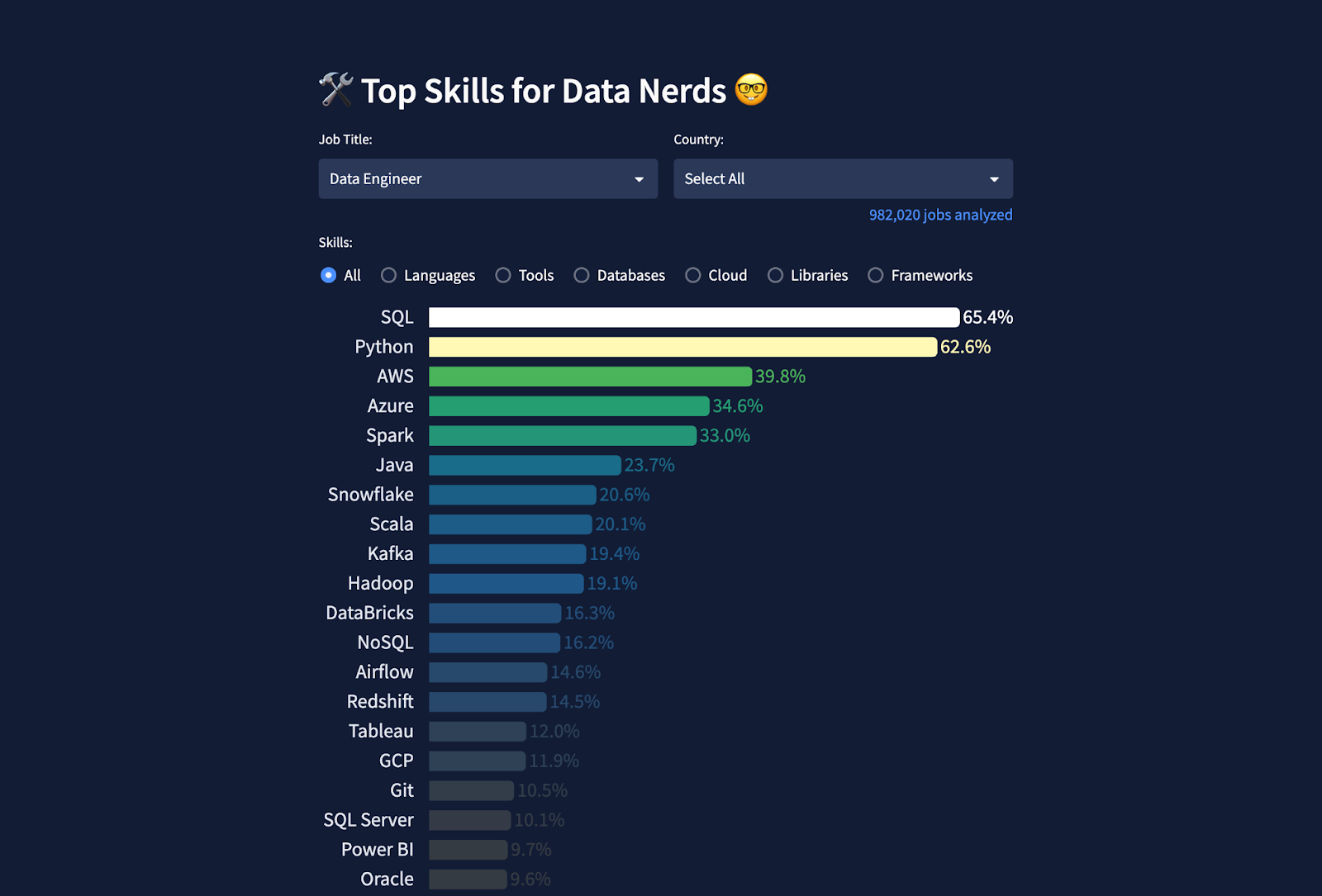
Python is among the top 5 essential skills for a data engineer. Its simple syntax makes it super friendly even to beginners.
Python’s extensive ecosystem of frameworks and libraries, such as pandas, numpy, and Airflow, supports diverse data engineering tasks.
But here, I'll walk you through some of the key concepts I use daily as a Data Engineer, along with practical example:
GitHub - nataindata/python-for-data-engineer: How to use Python for Data Engineering
How to use Python for Data Engineering. Contribute to nataindata/python-for-data-engineer development by creating an account on GitHub.
 nataindata
nataindataMain Python concepts for Data Engineer:
1. Core Python Basics
- Data Types & Structures: Lists, tuples, dictionaries, sets, strings.
- Control Flow: Loops, conditional statements (if-else, for, while).
- Functions: Defining, using, and understanding scopes (global, local), lambda functions.
- Error Handling: try-except-finally blocks, logging errors.
- File Handling: Reading and writing files (open(), with statement).
2. Data Manipulation
- Pandas: A critical library for data manipulation. Learn:
- DataFrames and Series manipulation.
- Filtering, aggregating, and pivoting data.
- Handling missing data and performing joins/merges.
- NumPy: Essential for numerical computations and working with arrays.
3. Database Interaction
- SQL Integration: Using libraries like sqlite3, SQLAlchemy, or psycopg2 to:
- Write queries.
- Interact with relational databases like PostgreSQL, MySQL, or SQLite.
- Work with ORMs (e.g., SQLAlchemy).
- NoSQL Databases: Interfacing with systems like MongoDB using pymongo.
4. Automation and Scripting
- Writing Python scripts for:
- Automated ETL pipelines.
- Data ingestion tasks (e.g., pulling data from APIs, scraping).
- Scheduling jobs using tools like Airflow or Luigi.
5. Working with APIs
- REST APIs: Using requests or httpx to interact with APIs.
- JSON Handling: Parsing and processing JSON responses.
6. Cloud and Big Data Tools
- Cloud SDKs: Libraries like boto3 (AWS), google-cloud-python (Google Cloud), or Azure SDKs.
- Big Data Libraries: Knowledge of PySpark or Dask for handling large-scale data.
7. File Formats
- Parsing and processing various data formats:
- CSV: csv, Pandas.
- JSON: json module.
- Parquet and Avro: Libraries like pyarrow or fastparquet.
8. Parallelism and Optimization
- Multiprocessing: Using multiprocessing and concurrent.futures for parallel processing.
- Asynchronous Programming: asyncio for I/O-bound tasks.
9. Testing and Debugging
- Unit Testing: Using unittest, pytest.
- Debugging: Mastering tools like pdb or IDE debuggers.
10. Best Practices
- Version Control: Familiarity with Git.
- Code Quality: Writing clean, modular, and PEP 8-compliant code.
- Documentation: Using docstrings and tools like Sphinx.
11. Workflow Orchestration and Tools
- Airflow: Building and managing workflows.
- Docker: Containerizing Python applications.
- Kubernetes: Deploying Python-based solutions.